This is the note for the course Neural Networks in Coursera.
Course Link: https://class.coursera.org/neuralnets-2012-001/lecture
Why do we need machine learning
In a typical program, we define a lot of rules, which are represented by ‘loop’, ‘if condition’ and ‘assignment’. If the program is correct, given some inputs, we can always get expected accurate outputs.
However, in some real world scenarios, it is very difficult to describe judging rules for some questions. For example, handwriting recognizing, speech recognizing and so on. The only thing we can do is to give the program a lot of inputs and their corresponding outputs. And let the program itself learn the rules behind.

Usually the rules learned by program is called model, which is represented by one or several parameter matrices.
What are neural networks
Parallel computation, generate real number value than discrete value.
Some simple models of Neurons
Linear neurons
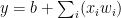

It is simple but computationally limited.
Binary threshold neurons
- First compute a weighted sum of the inputs
- Then send out a fixed size spike of activity if the weighted sum exceeds a threshold.
- McCulloch and Pitts thought that each spike is like the truth value of a proposition and each neuron combines truth values to compute the truth value of another proposition!
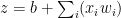
y = 1 if z >= 0
y = 0 otherwise

Rectified Linear Neurons (Linear threshold neurons)
They compute a linear weighted sum of their inputs.
The output is a non-linear function of the total input.

y = z if z > 0
y = 0 otherwise

Sigmoid neurons
These give a real-valued output that is a smooth and bounded function of their total input.
- Typically they use the logistic function.
- They have nice derivatives which make learning easy.


Stochastic binary neurons
These use the same equations as logistic units.
- But they treat the output of the logistic as the probability of producing a spike in short time window.
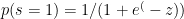

A simple example of machine learning

The picture above depicts a simple neural network with one input layer and one output layer — no hidden layers.
In fact, it’s a linear regression. The intensity of each pixel in the weight image (which we will call weight matrix later) indicates the weight of the corresponding pixel contributes to the class.
We notice that in the weight matrix of class 7 and class 9, weight below the half horizontal line is quite small. It indicates that pixels below the half horizontal line doesn’t matter a lot, because the handwriting of 7 and 9 below the half horizontal line varies a lot. So our neural network only focus whether the handwriting has a horizontal line with a sharp turn at the top when recognizing 7, or a loop when recognizing 9.
It sounds nice and simple, but it has some vital drawbacks. Please see the example below.

Even though the images from category 2 contain horizontal bars, none of the training examples ever overlap with the middle row of pixels so category 2 will get 0 “votes” for this example. Conversely, all three of the images from category 1 have a pixel that overlaps with the middle row so the test image will receive 3 “votes” for category 1.
The simple learning algorithm is insufficient, because the two layer network with a single winner in the top layer is equivalent to having a rigid template for each shape.
- The winner is the template that has the biggest overlap with the ink.
The ways in which hand-written digits vary are much too complicated to be captured by simple template matches of whole shapes.
- To capture all the allowable variations of a digit we need to learn the features that it is composed of.
- Add more layers to learn higher abstraction of digit features.
Three types of learning
Supervised learning
- Learn to predict an output when given an input vector and a target output.
- Regression: The target output is a real number or a whole vector of numbers.
- The price of a stock in 6 months time.
- The temperature at noon tomorrow.
- Classification: The target output is a class label.
- The simplest case is a choice between 1 and 0.
- Regression: The target output is a real number or a whole vector of numbers.
Unsupervised learning
- Discover a good internal representation of the input.
Reinforcement learning
- Learn to select an action to maximize payoff.
Neural Networks
Hypothesis function presentation
For a single variable x1, 2 order regression:

For 2 variables x1, x2, 2 order regression:

For x variables, r order regression, we need 
The growth of the number of new features we get with quadratic terms is

The features grows fast. Neural networks offers an alternate way to perform machine learning when we have complex hypotheses with many features.
Model Representation I
Each neuron is basically a computational unit that take input (dendrites) as electrical input (cakked spikes) that are channeled to outputs (axons)
In neural networks, we use the same logistic function as in classification
