https://www.coursera.org/learn/probabilistic-models-in-nlp/lecture/ZTOqC/overview
probability sequence models, markov chain
Week 1 – auto correction
The goal of this week is to build an auto-correction system. It is context free. It uses the edit distance and word probability.
- identify misspelled word
- not in a dictionary.
- (advanced) take the context (surrounding word) into account.
- find the words candidates with 1, 2,3,… edit distance. These candidates might or might not be a valid word
- insert letter
- edit letter
- remove letter
- switch two adjacent letters
- Filter candidates
- remove word candidates that are not in the dictionary
- Calculate word probabilities.
- calculate the word frequency (no context is considered)
How to consolidate the edit distance and word probabilities? we have two values to rank.
In the course 1, we use naive bayes which assumes each word appears in a text independently.
Now we drop this assumption by using the markov chain.
Minimum edit distance
cost: insert 1, remove 1, replace 2 (it’s equivalent to insert then remove a letter)
D[i,j]= min (D[i-1,j] + 1, D[i, j-1] + 1, D[i-1, j-1](if A[i] == B[i]) or D[i-1, j-1] + 2)
Use dynamic programming to solve the minimum edit distance problem.
核心思想
通过edit distance (primary criteria)和词汇的probability/frequency (secondary criteria)来做auto correction
局限性
忽略了上下文,只考虑词汇的frequency。和week2所学的结合,我们应该tag上文,推导出需要correct的词汇很可能是什么词性。
Week 2 – Hidden markov chain and part of speech taging
Transition matrix
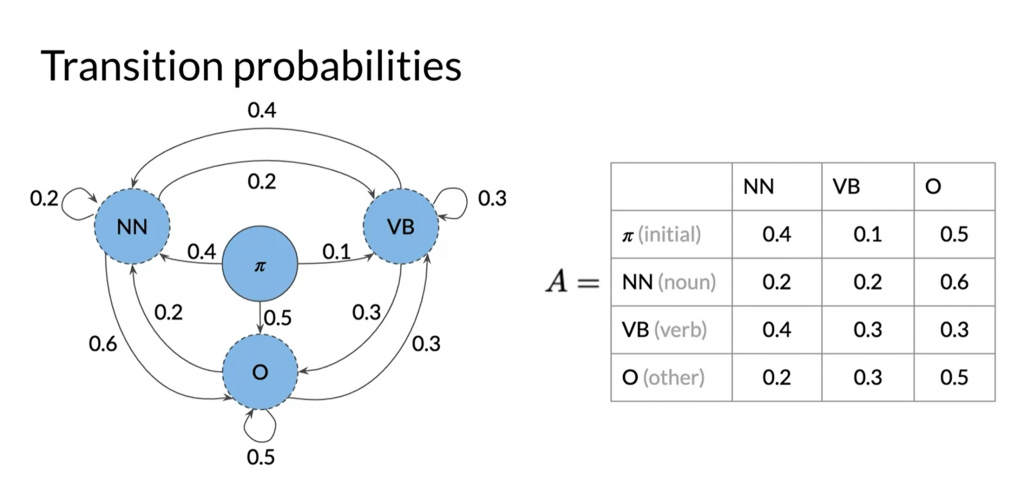
These probabilities are calculated via tagged corpus.
Emission matrix
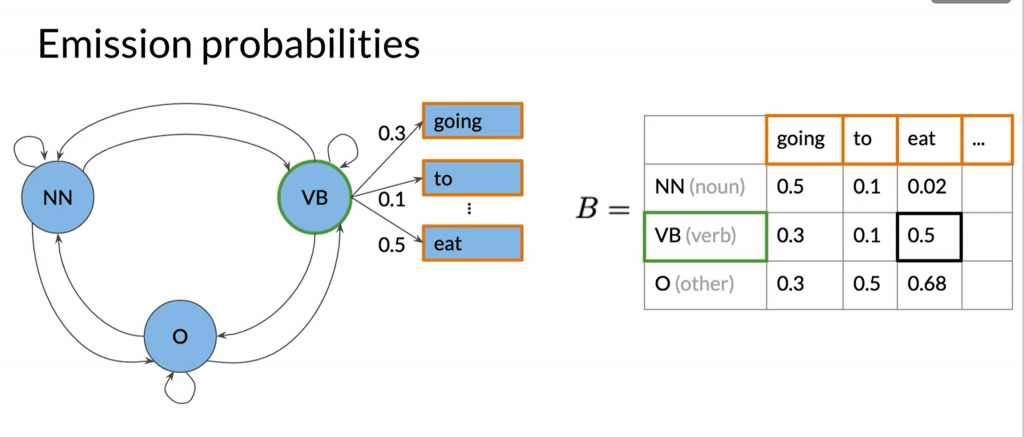
This is calculated via the tagged corpus as well.
The hidden markov model consists of States, Transition matrix and emission matrix.
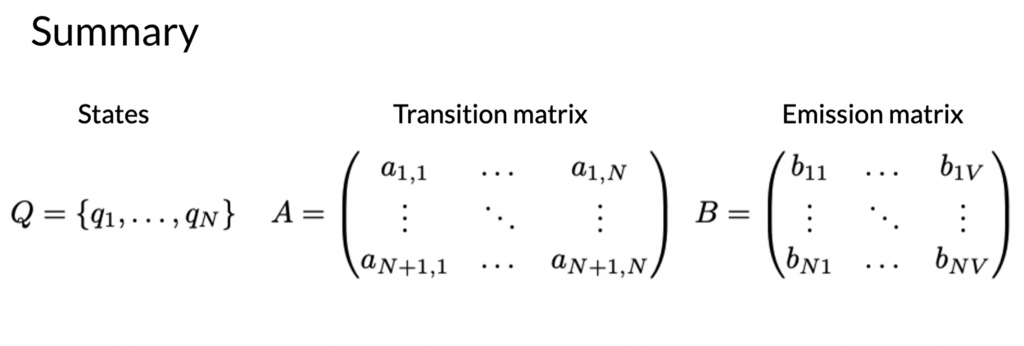
Generating the transition matrix and emission matrix
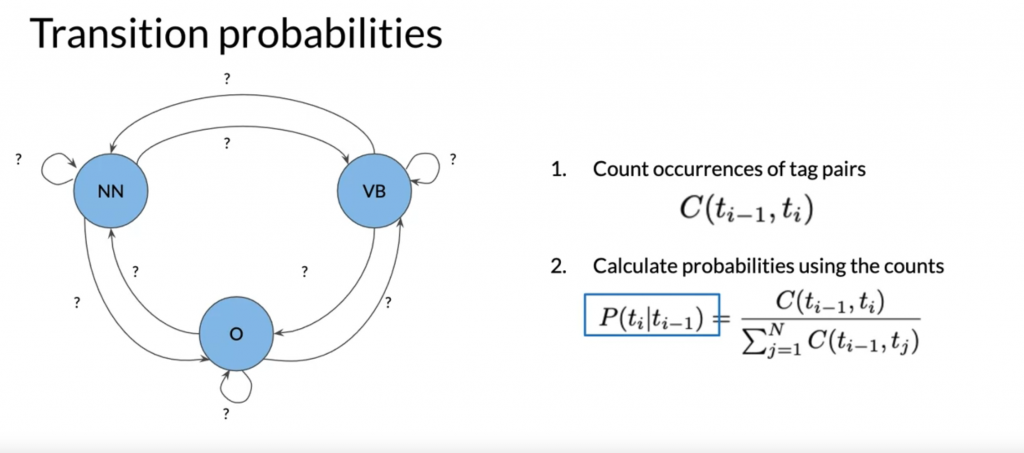

The transition matrix and emission matrix are generated from the corpus.
Teacher drinks coffee
<s>NN VB NN</s>
I’m going to eat
<s>NN VB O VB</s>
Who is your mother
<s>NN VB NN NN</s>
We use <s> </s> to denote beginning and ending of a sentence
Given the corpus about we can get the transition matrix

P(VB|NN) (count(NN -> VB) / count(NN) 当NN出现了,后面接的是VB的概率) = 3 / 6
P (NN | VB) = 2 / 4
P (NN|<s>) = …
P….
Regarding to the emission matrix
P (‘Teacher’|NN) = 1/6
P….
How to use the transition matrix and emission matrix to tag the sentence – Viterbi algorithm
Algorithm definition: Given the sentence and the transition/emission matrix, tag the whole sentence to maximize the probability.
Use dynamic programming to maximize the probability. Very similar to the minimal edit distance with the path preserved.
3 steps in the viterbi algorithm: initialization, forward pass, backward pass
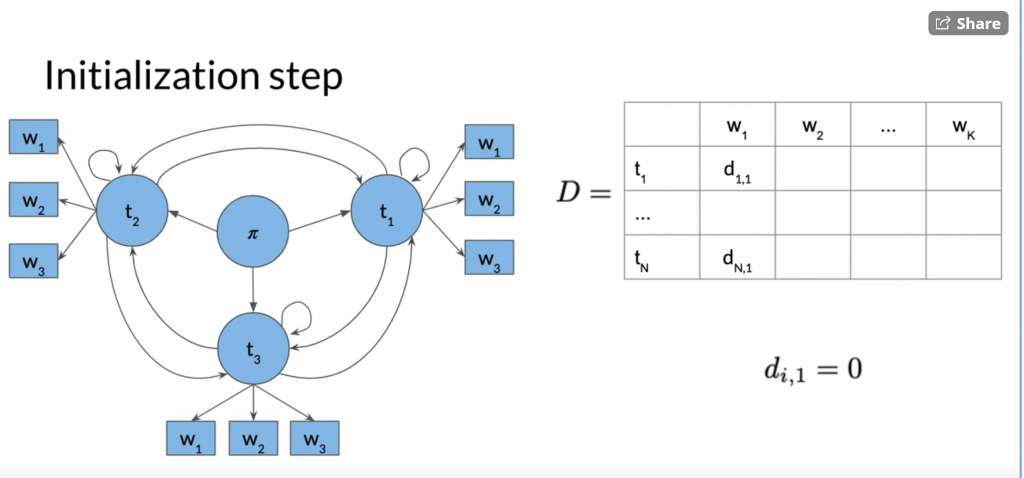
Initialization
Initialize two matrix, C and D. C_i_j stores the maximum probability if we choose tag i (t_i) to emit the word at position j (w_j).
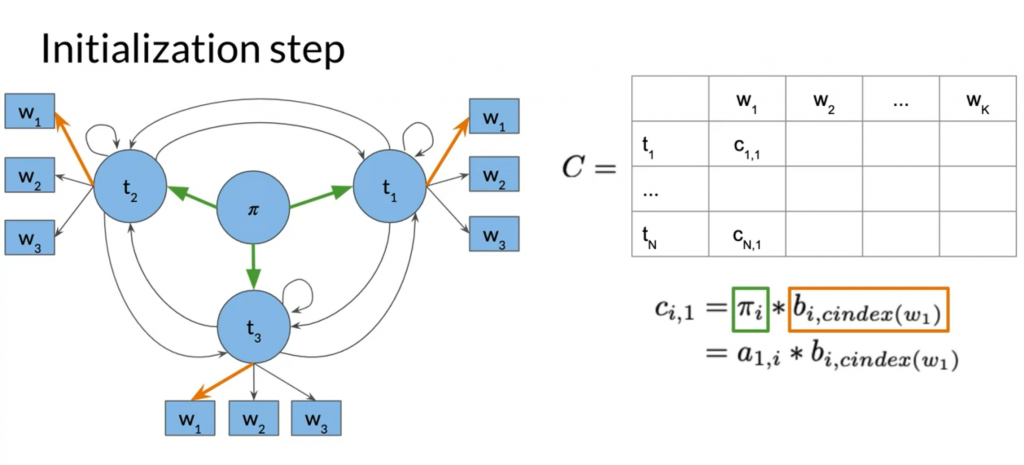
D_i_j stores the which cell in column j-1 generates the maximum probability in C_i_j. D stores the path for backward pass.
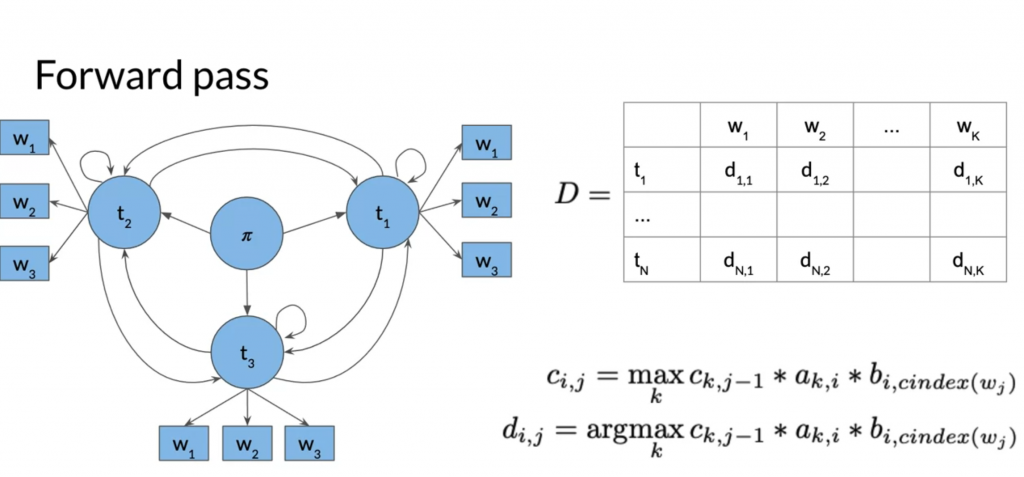
Forward pass
Forward pass populates the C and D.
a_k_i is the transission probability from t_k to t_i
b_i_cindex(w_j) is the emission probability to emit w_j at t_i
d_i_j stores the k that maximizes c_i_j
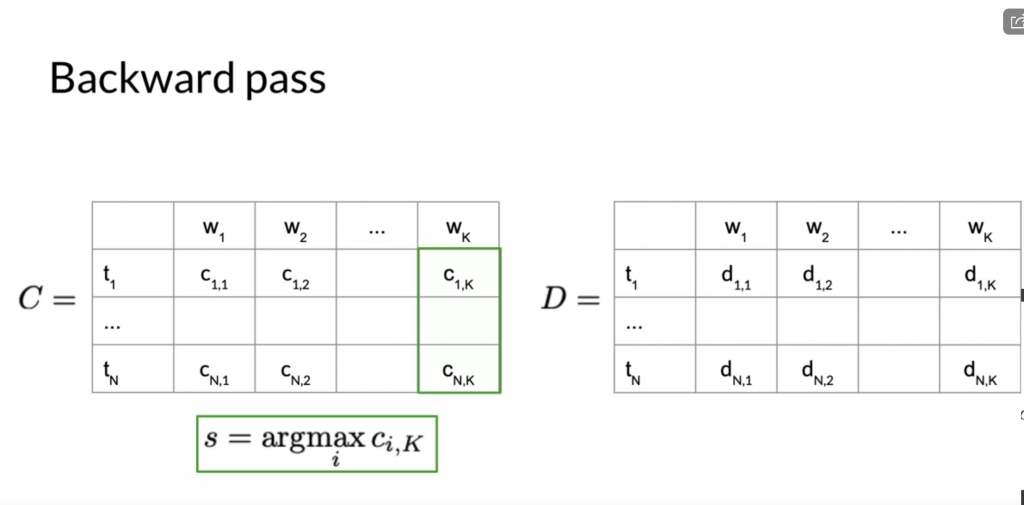
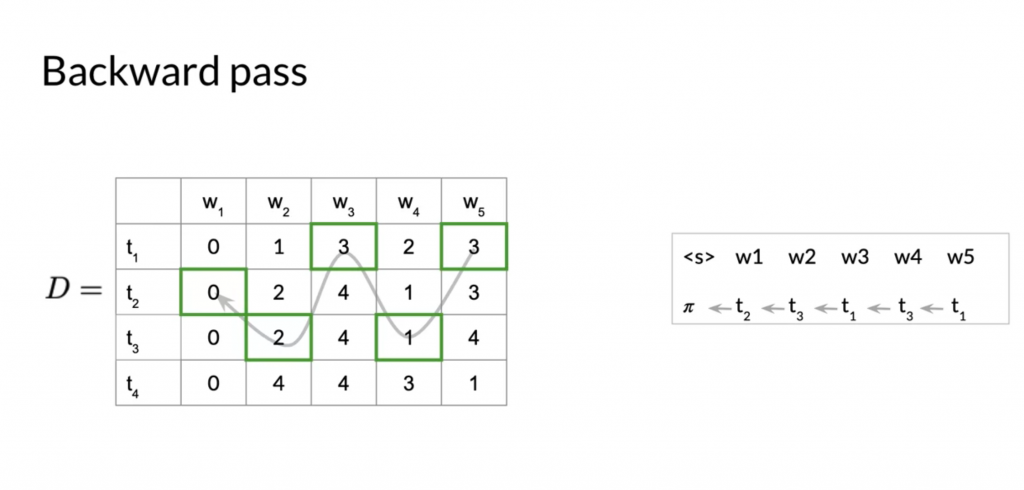
Backward pass
Backward pass is to extract the tag path from matrix D. We starting at the right most column and the row whose corresponding cell in C contains the greatest value.
Two implementation issues

Final thoughts
用markov chain做sentence tagging. 其核心思想是一个单词的词性(tag)的概率和它的上文有关。整个句子的tagging的目的是最大化整个句子的markov chain tagging的probability。
局限性
- 必须train在一个corpus上。对于没见过的词,它只能通过词缀(-ize, -tion)来推测它是什么词性。如果词缀也推测不出来的话,那就只能忽略emission matrix,转移到最大化ti的tag上。
- 如果句子中有某个词的语法错误,整个句子的tagging都会受到影响,因为它做的是全局最优。
扩展实验
搜集english dictionary,做一个检测输入的单词长得像不像英文的预测机。
这个要如何实现?你可以写一个检测像不像英文句子的模型;但如何写长得像不像英文单词的模型?
week 3 – autocompletion and language model
Definition of language model.

Use cases of a language model

N-gram model
An N-gram is a sequence of N words
sequence notation: w^<end index>_<start index> , both inclusive

Bi-gram probability



简而言之,计算N-gram概率时,用N-gram的词频除以它N-1前缀的词频。
Sequence probability
Given a sentence, what is its probability occurring in the language?

From the equation in the N-gram probability above, we get
P(A, B, C, D) = P(D|A,B,C) * P (A, B, C)
= P(D|A, B, C) * P ( C | A, B) * P (A, B)
= P(D|A, B, C) * P (C | A, B) * P (B|A) * P(A)
Problem: The corpus probably don’t have the exact subsequence like (A, B, C) or even (A, B).
Solution: we run approximation probability

So, using Bi-gram approximation, we get P(A, B, C, D) = P(A) * P(B|A) * P(C|B) * P(D|C)
How to calculate P(A)? We can not use the frequency of A divided by the would count since P(A) means the probability of A occurs at the beginning of the sentence.
We add <s> to mark the start of the sentence. Then P(A) becomes P(A|<s>)

Similarly we add </s> to mark the end of the sentence. Otherwise C(x w) !== C(x) in the pic below

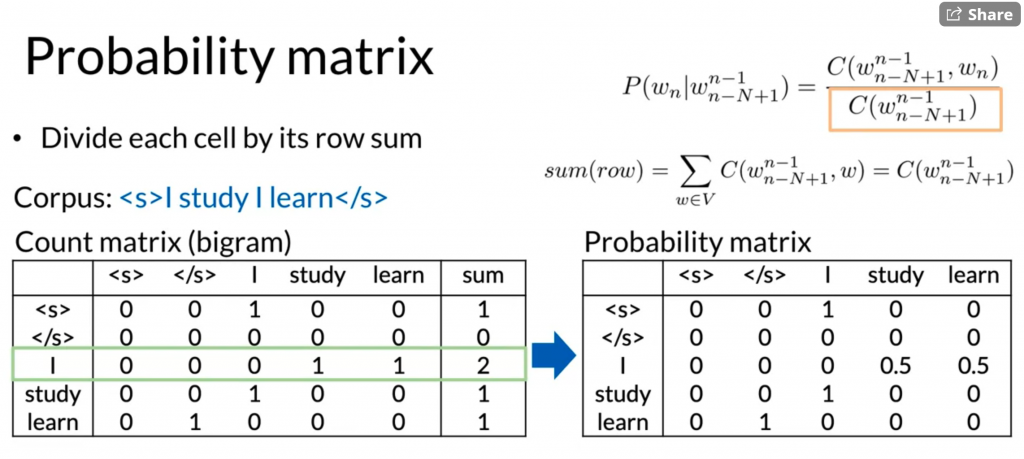
N-gram language model
count matrix [i][j] stores the count for the bi-gram vocab[i], vocab[j]
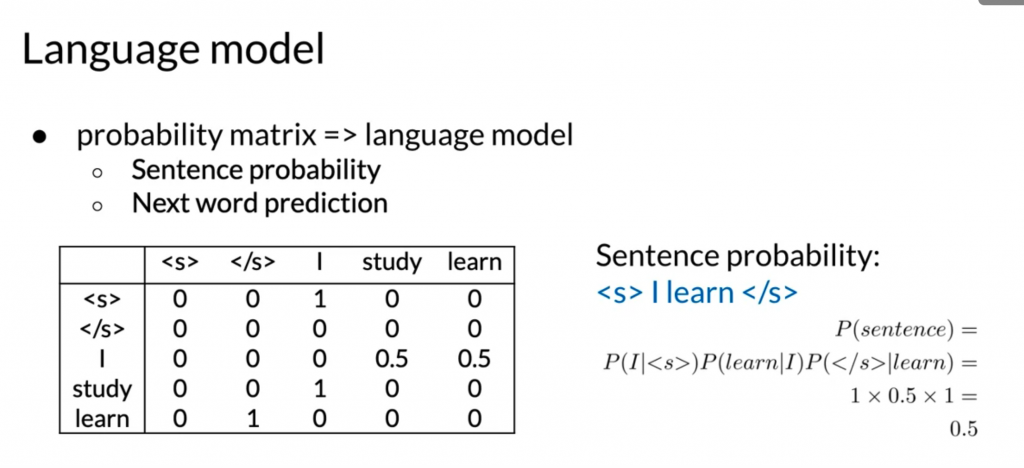
With this language model built on top of bi-gram, we can calculate sentence probability and do next word prediction. We can also do sentence generation.
How to evaluate the quality of a language model?
We calculate the perplexity. It models the entropy of the language model. The lower the perplexity, the higher the language model quality.

Summary: 这有点像,用训练好的模型去评价训练集的sentence的probability。probability越高,证明这个模型越有效。
对于bigram而言,如下图

a good model’s perplexity is between 20-60
Some researchers uses log perplexity to avoid multiplying small values (underflow) in computer.
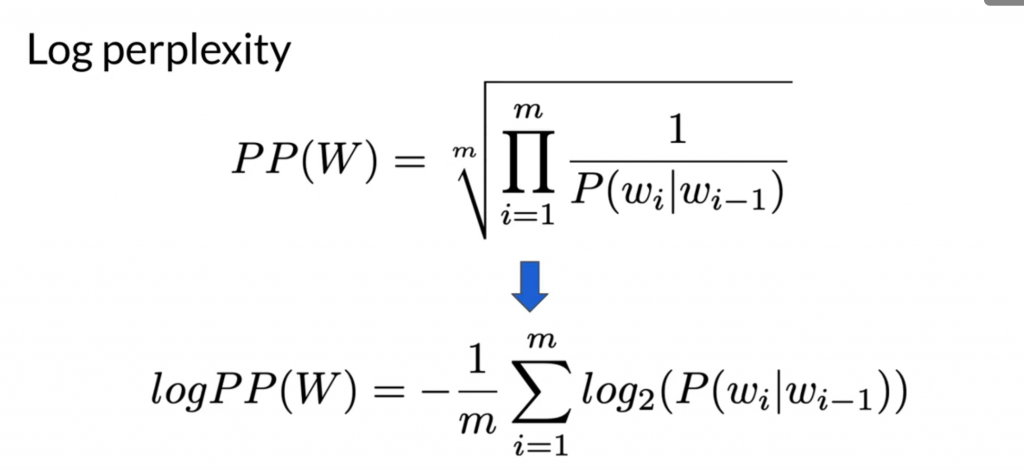
Out of vocabulary words
The vocabulary in the training set might not contain all words in the test set and realworld.
To handle the out of vocabulary words. we first build up the vocabulary. By using the following criteria:
- defined a min word frequency f, we set the word to <UNK> in the training set if the frequency is less than f.
- define a vocabulary size V, order the words by frequency. Remove low frequency words that are outside of V.
Note: the <UNK> shall be sparing. 稀疏的.And only evaluate LMs with same V.

Thought: 其实就是把<unk>归成一类特殊的字符。并且把training set中低频的词也作为UNK,所以可以学习出它的pattern来。
Smoothing
Problem: some n-gram pairs might be missing in the training set.

Solution: Laplacian smoothing (add 1, or add k smoothing)

The corpus should be large to not let the “plus 1” distort its distribution.
The other solution is backoff. We use N-1 gram with a discount value (magic number 0.4, stupid backoff) to estimiate the N gram probability.

The other alternative to backoff is interpolation.
question: why do we know P(chocolate| John drinks)? and still calculate P^(chocolate|john drinks)?
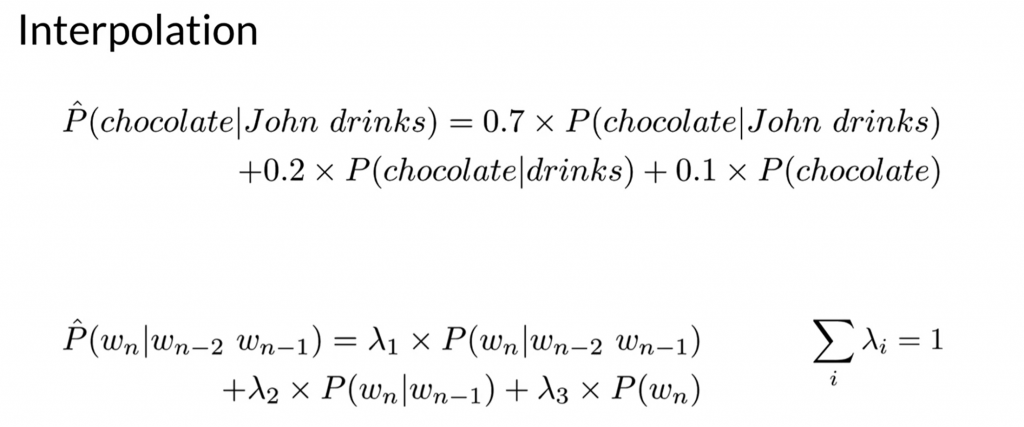
Week3 final thoughts
做n-gram时不用给词做stem;但在twitter情感分析时,却需要给词做stem。我的理解是,因为
- 我们假设词形变化对语义的情感无影响或影响很小。(happy, happ, happiness同义或相似意思)
- n-gram时,我们的输出(auto-correction)是需要词的原本形式,而非stem后的形式。
另一个检测是否需要stem的方法,如Andrew Ng所说,是用人眼看data。如果stem之后,人类还能进行所要求的任务的话,甚至可以做的更好的话,那么就stem。如果人都做不出来所要求的任务的话,那就不要做stem。
Week4 word embeddings
one hot vector embedding. Simple, but no semantic relationship embedded.
Basic Word embedding methods
word2vec(google, 2013)
- continues bag of words (CBOW) – shallow neural network
- continues skip-gram / skip-gram with negative sampling (SGNS)
Global vectors (GloVe) (standford, 2014)
fastText (facebook, 2016)
- supports out-of-vocabulary (OOV) words
Advanced word embedding methods
Deep learning, contextual embeddings
- BERT(Google, 2018)
- ELMo (Allen Institute for AI, 2018)
- GPT-2 (OpenAI, 2018)
Tunable pre-trained models available on the internet.
Thoughts: For word2vec, GloVe or fastText, it maps a single word to a vector, regardless of its context.
For BERT, ELMo, GPT-2, it maps a single word in a sentence to a vector. You can not map a single word without context to a vector using these methods.
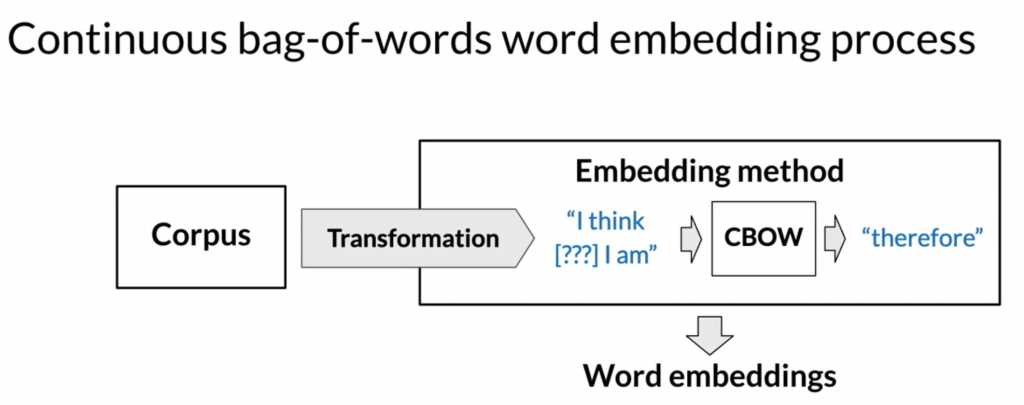
Continuous bag of words word embedding process
Assumption: semantically similar words are surrounded by similar words.
一个词的语义,是由它周围的词决定的。类比于一个房子的房价,是由周围的房价决定的。一个人的高度,看他周围交往的朋友。
某个事物的特性,由它周围的事物决定。
Cleaning and tokenization matters
- letter case – all lowercase
- number – drop it or convert to a special char <NUMBER> depending on your use case
- punctuations – stopping punctuations all converts to ‘.’, such as ? ! !! ??.
- drop all other non stopping punctuations, such as ” ‘ ,
- special characters – emoji for example.
Mapping words to vectors
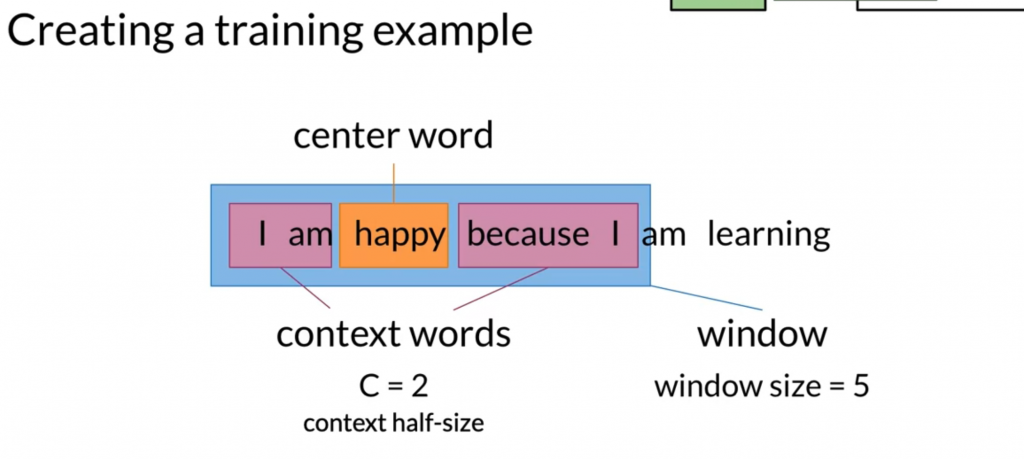
Given the corpus “I am happy because I am learning” and half window size = 2. The context words are “am happy I am” and the center word is “because”.
We average the one hot vectors of the context word as the input vector.
Question: why not using a randomly initialized vector as its initial value? but uses the averaged one hot vector as the input vector?
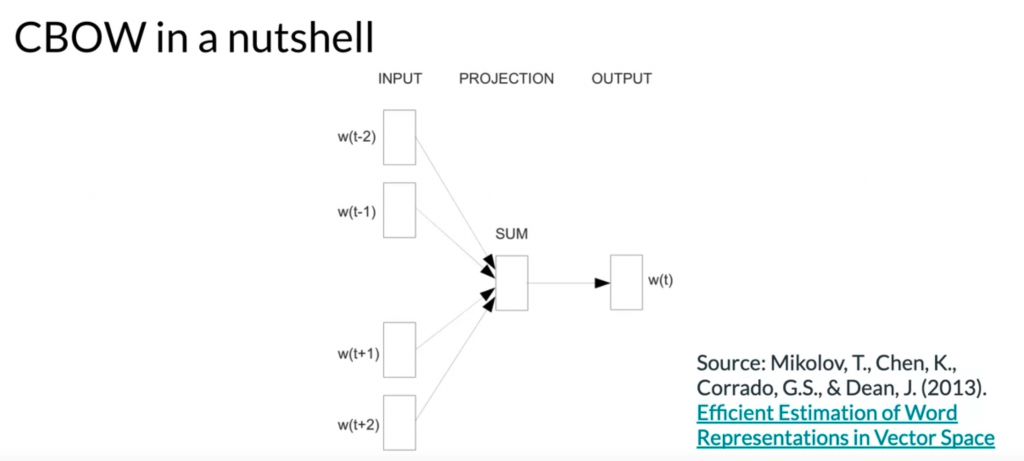
CBOW architecture
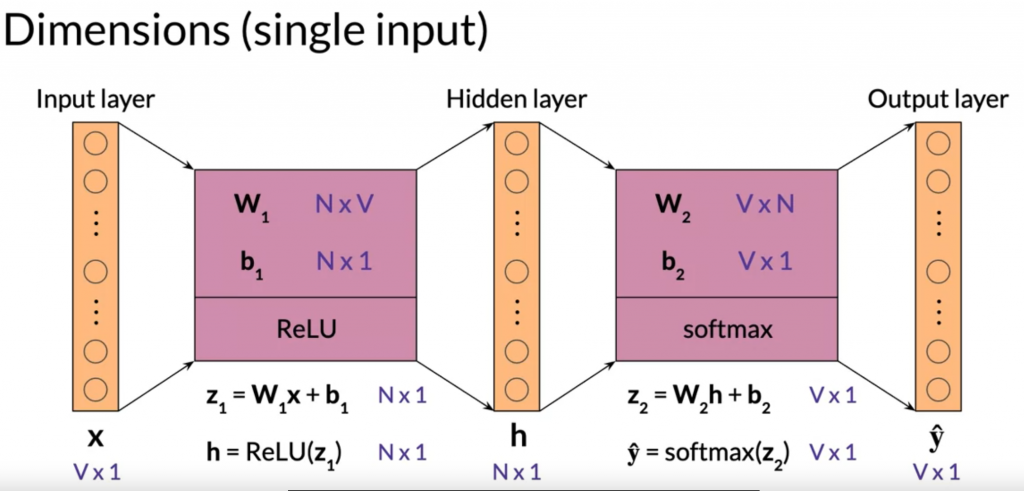
Reference readings: ReLu is not a linear function , Why using softmax rather than standard normalization, activation function list.
Cross entropy loss
We only care about if the y_hat is high for the correct label y. We want to maximize the y_hat.
The cross-entropy loss listed in the pic below is a general form of the binary cross-entropy.
More detailed explanation can be found here: https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html#cross-entropy

thoughts:
softmax和其他激活函数,如ReLu、sigmoid不同。它的输入是一个vector,输出是一个vector。而其他激活函数的输入和输出都是一个scalar。即使在平行计算中,输入一个vector,做的也是element wise的operation。
cross-entropy loss

multiclass loss和binary class loss的cross-entropy loss的公式看起来不同,但实际上是一回事。binary class loss的公式是multiclass loss的特殊形式。
它特殊在,yhat是class1的预测值,那么1-yhat就是class2的预测值。binary indicator y_o_c 被拆解成了 y 和 1-y.


最后的embedding vector有三种表示方法:
用W1,用W2,或者两者平均一下放一起。
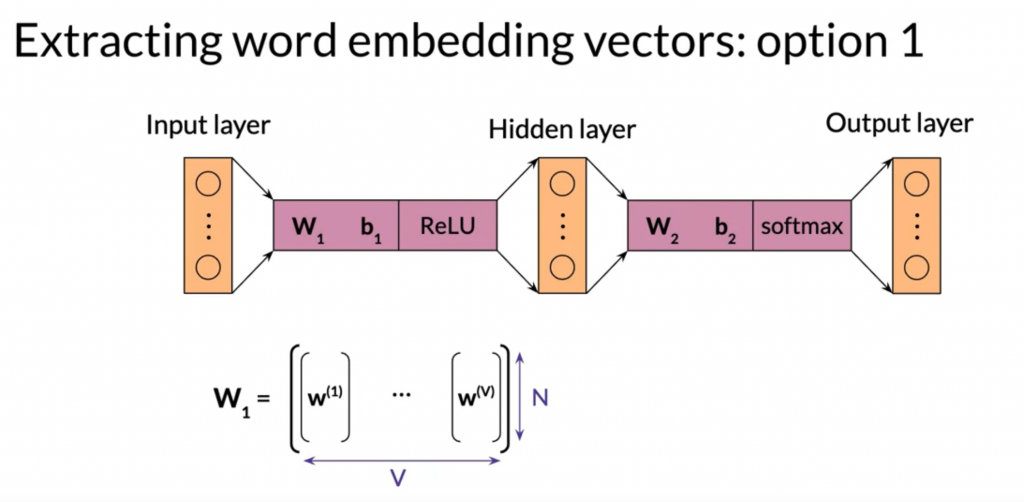
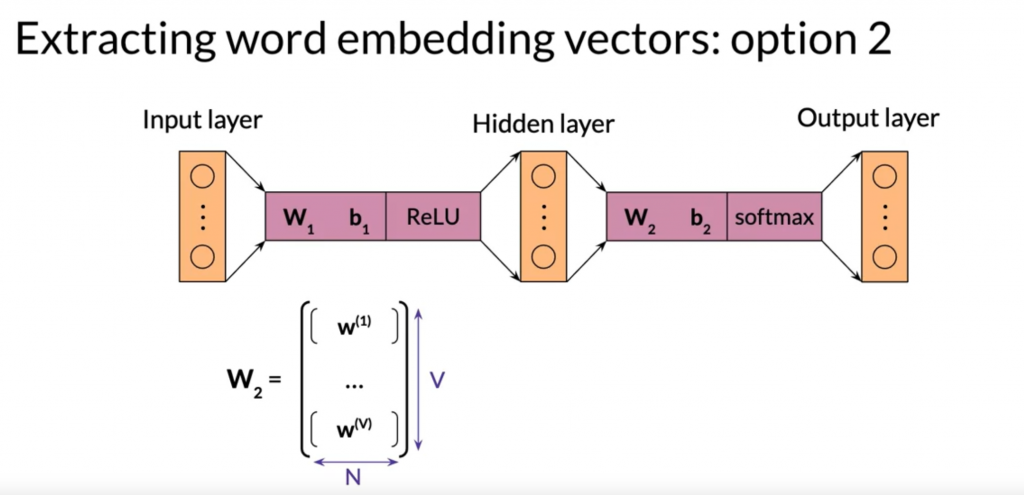
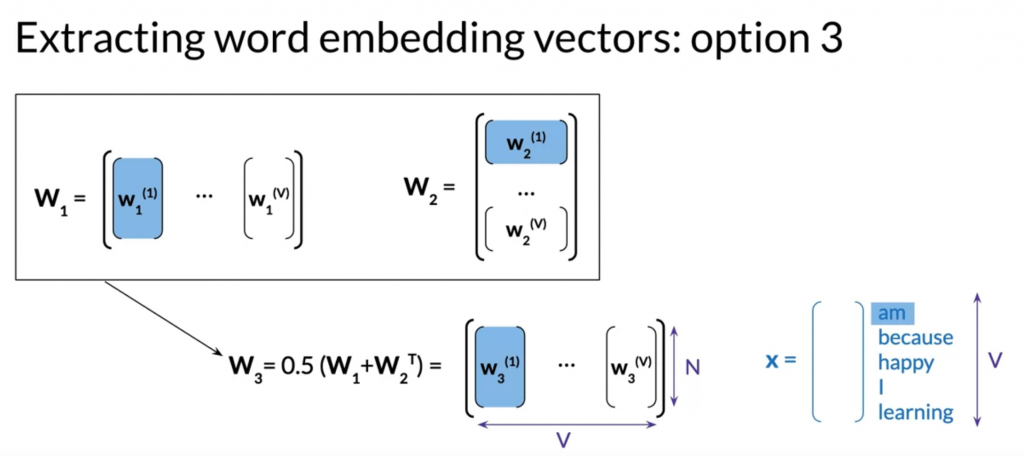
Evaluating the word embeddings
Intrinsic evaluation – 找到词之间的相对关系

注意:可能有多个词都可以是正确输出。
Clustering – 语义相似的词应该离得比较近,人工去看这些cluster。
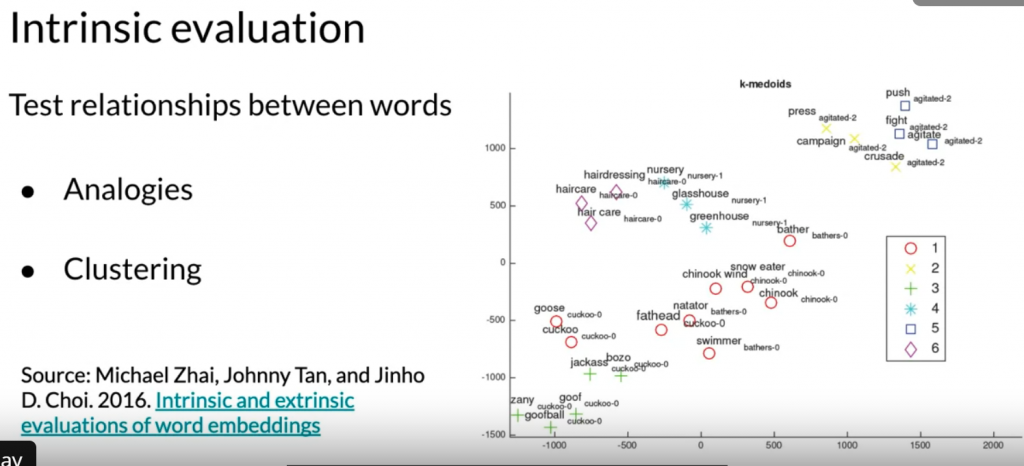
visualizing – 人工地去看这些词,语义相近的词是不是在一起。
Extrinsic evaluation
test word embedding on external task
e.g. named entity recognition, parts-of-speech tagging.
+ evaluates actual usefullness of word embedding
– time consuming
– hard to trouble shoot when the performance is poor.
Final thoughts
word embedding无法处理多义词。实际上,词的语义与上下文有关,记语义为函数P,词为W,上下文为C。word embedding 假设 P(W),但实际上,是P(W, C)。
transformer解决了上下文的问题。