How to build a scalable system?
1.The most intuitive approach – single webserver and database
The system has a single webserver with a database
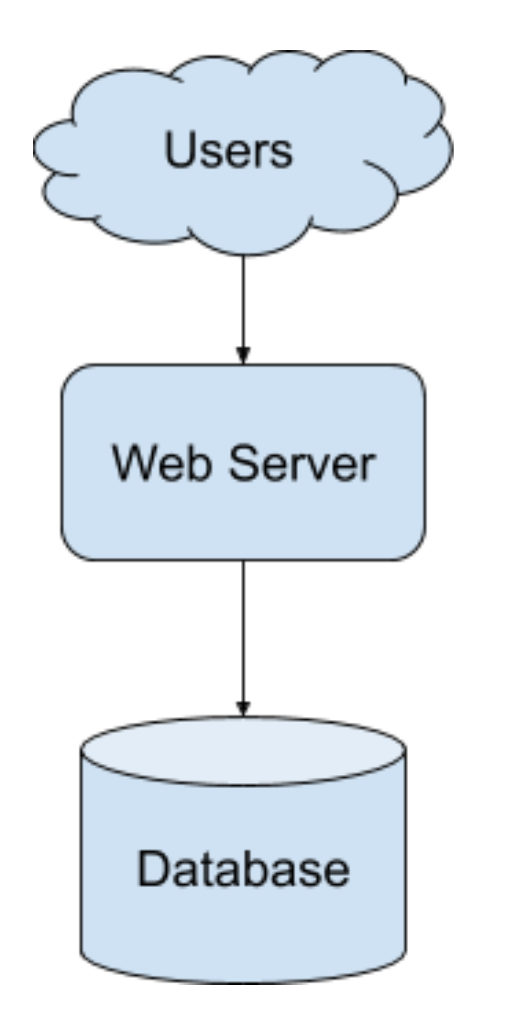
Cons of this design: The webserver and database becomes the bottleneck of the system to be scaled up.
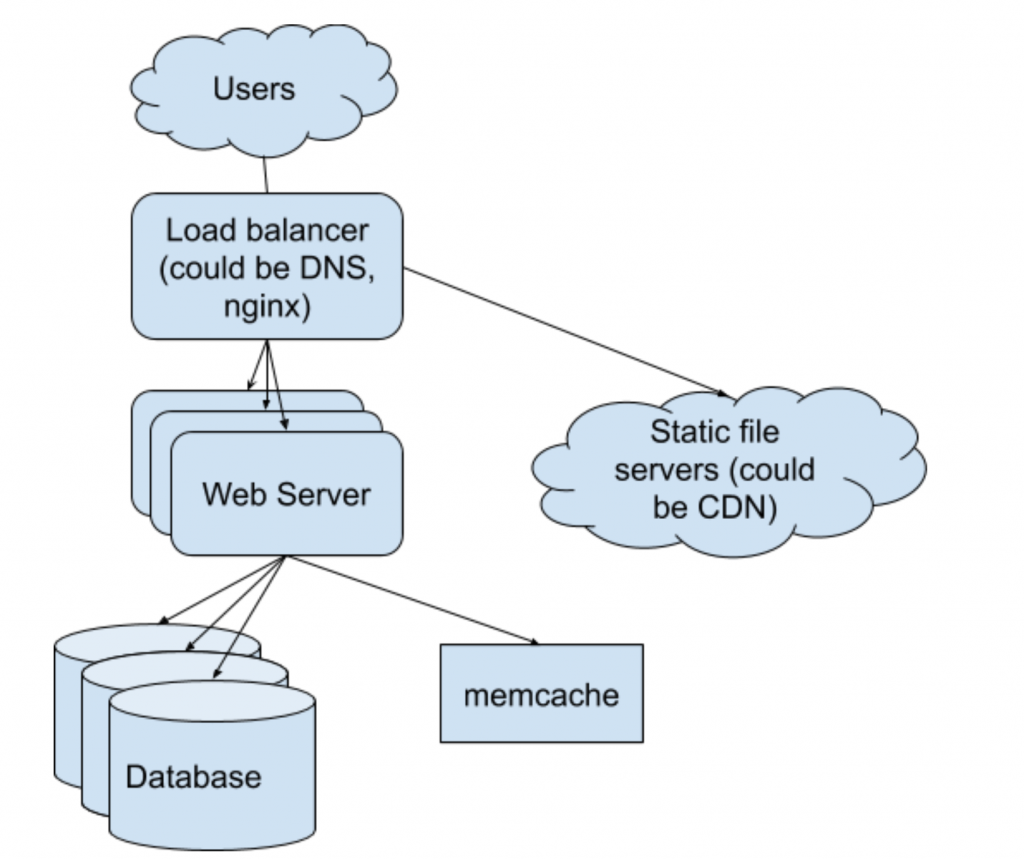
2. System with load balancer and CDN
Load balancer is added between user and webserver, which distributes the user traffic to different web servers to reduce the each webserver’s workload. The balancer could be Nginx, DNS, or something else.
Static files (CSS, HTML, JS, videos, photos, etc.) could also be cached in specific servers, like CDN, outside of the web server,
The first fetch of the static files could be slow cause the CDN need to fetch the data from the webserver. It becomes fast after cache is updated.
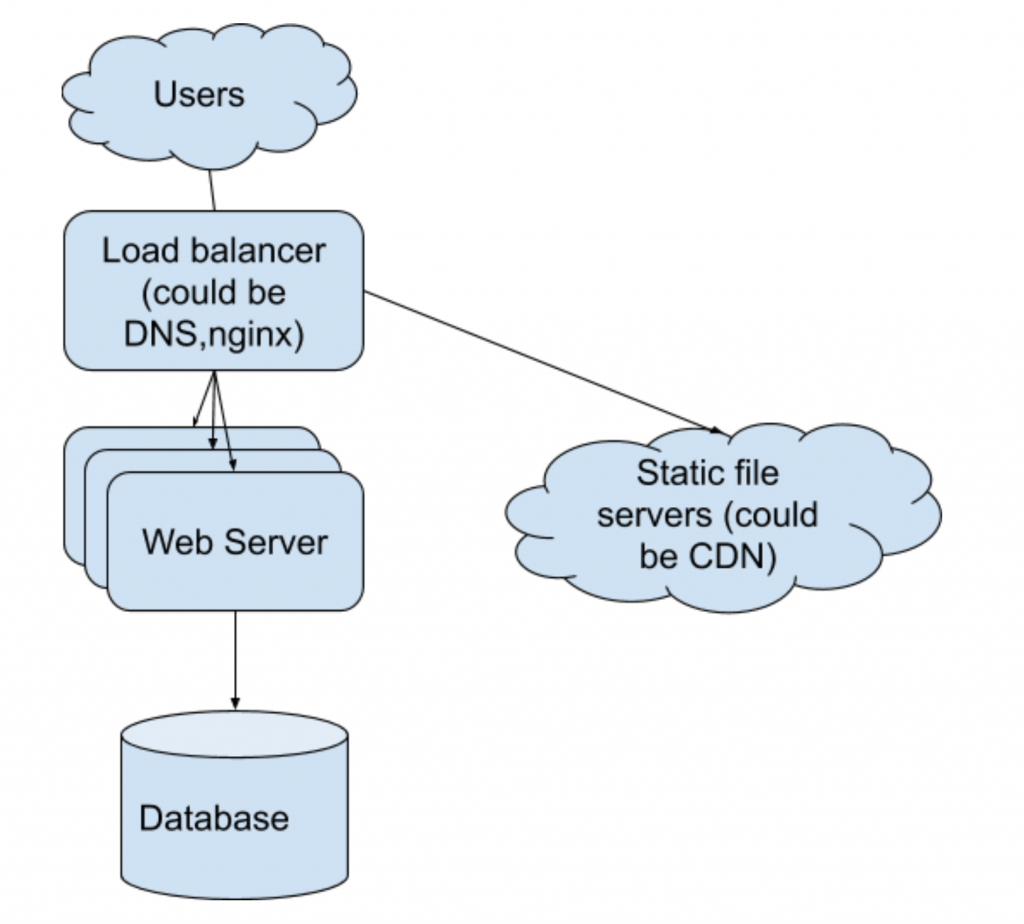
Cons: The database is still the bottleneck of the system.
3. System with load balancer, CDN, cache and distributed database
There are several ways to increase the speed for a single point database, like indexing and memcache.
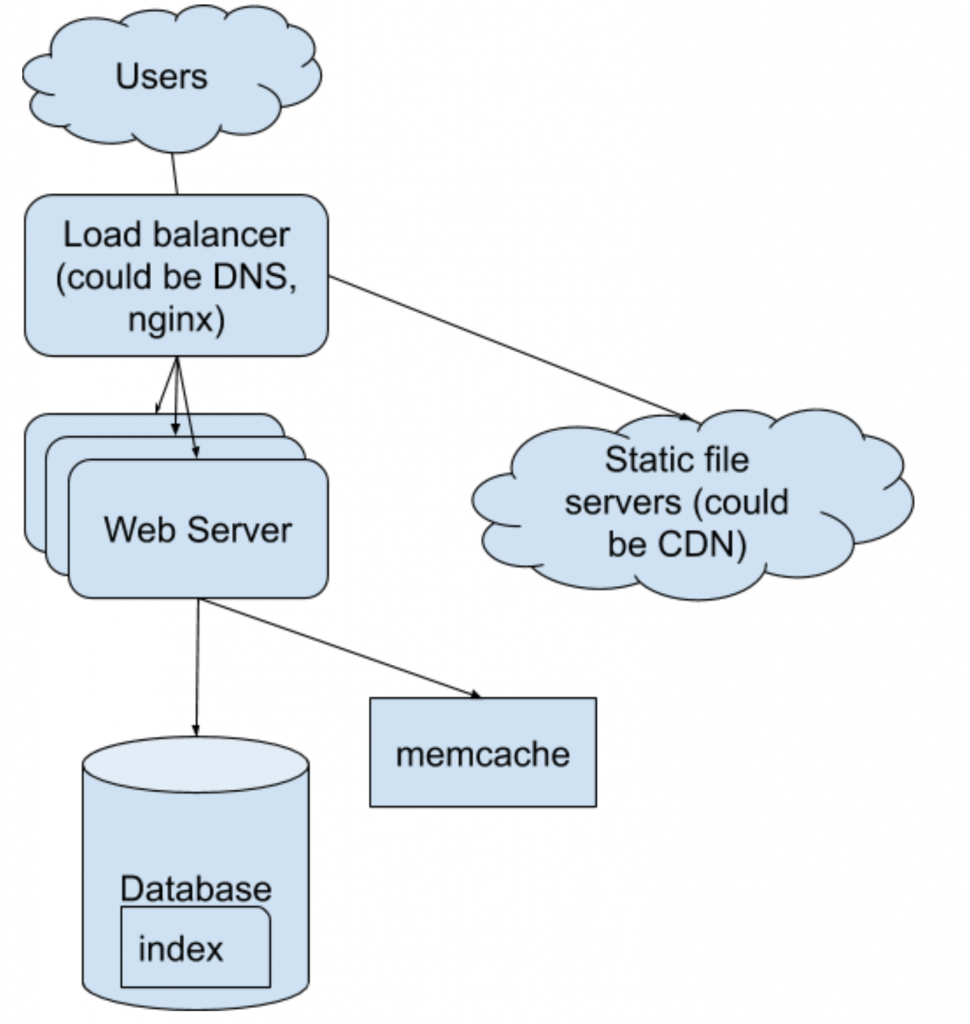
When it comes to distributed databases, there are more concepts to consider than the distributing the webserver, because database is stateful while webserver is stateless.
The first distributed database design is the master-slave model. There is a single master database which handles all the write operations and replicates its write operation to its multiple slaves. All the slaves, probably the master as well, handles the read operation. Depending the replication protocol, the read could be strong consistency or eventual consistency.
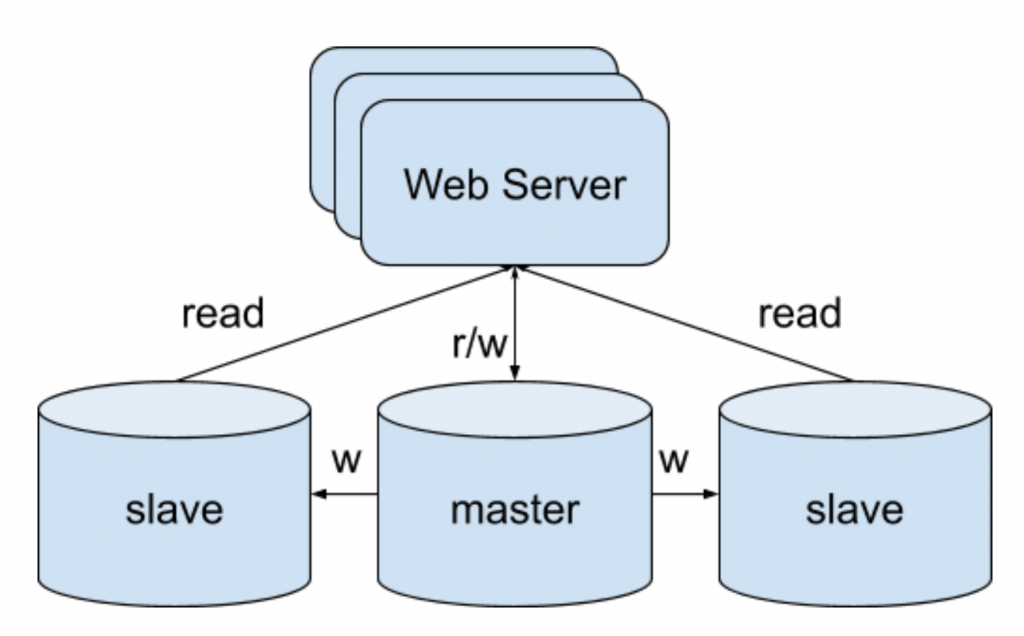
Cons of version 4: The master is still a single point of failure, it handles all the write operation.
There are two ways to further scale up the system, vertical sharding and horizontal sharding.
Vertical sharing is to partition the database by tables. You store different tables (or different columns) into different database instances.
Horizontal sharding is to partition the database by roles. You store different rows into different database instances.
For these two shardings, a mapping mechanism (hash function, for example) is needed to locale the database instance(s) for the data to be queried.
Reference:
Sharing Explained: https://www.digitalocean.com/community/tutorials/understanding-database-sharding