Blog : http://jalammar.github.io/illustrated-transformer/
Paper: Attention is all you need
What is transformer
From 1000 fts, it converts input to output. (usually used in machine translation)
From 100 fts, it consists of multiple layers of encoders and decoders.
From 10 fts, there are 6 layers of encoders and decoders.
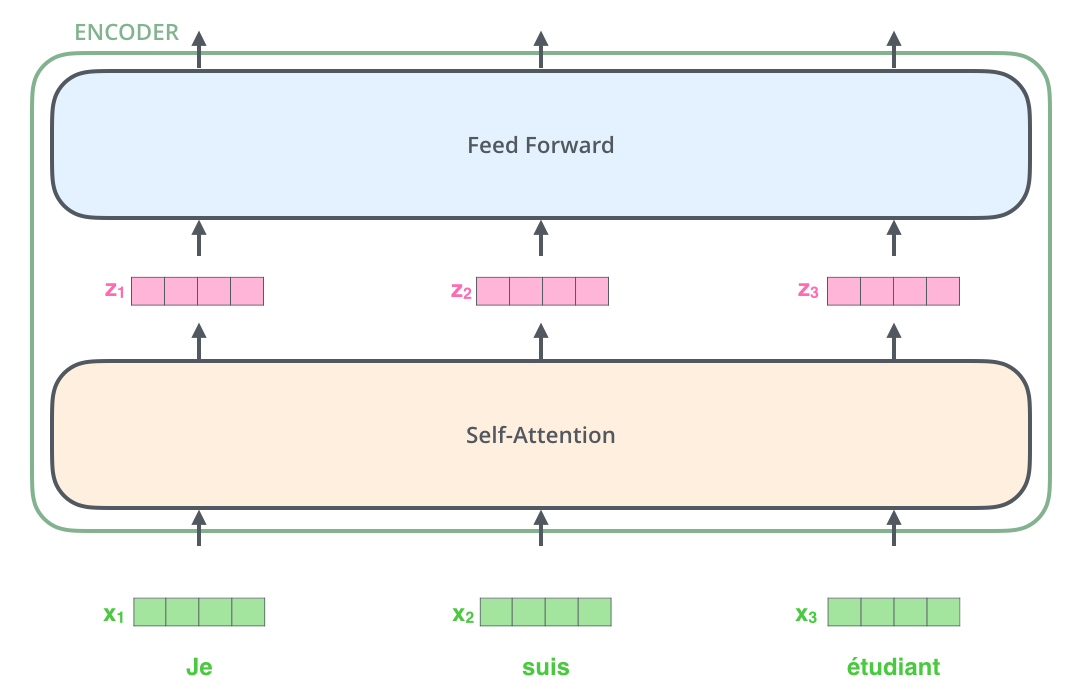
from 1 ft, each encoder has a self-attention layer and a feed forward neural network.
The input word is embedded into vectors, then fed into the self-attention layer, then into the feed forward layer.
word embedding embeds word into vector, and semantically similar words are closed to each other.
Before word embedding was invented, one-hot embedding is used where each word is embedded into a giant vector whose length is the vocabulary size and only one element is set to one.
Word embedding comes with two benefits:
1. Dimension reduction, thus saves computation resources.
2. Word semantics is encoded in the vector.
How the embedding is trained
CBOW (the word2vec approach) is short for Continues–Bag-Of-Words. it sets a window in the sentence, and remove one target word. It lets the model to predict the target word based on the context words within the window.
The vectors created by Word Embedding preserve these similarities, so words that regularly occur nearby in text will also be in close proximity in vector space.
How about use this idea to encode music notes? We can have a note -> vector embedding for each musician.
Self-attention represents to how much attention should the model pay to context words and the source word in the whole sentence.
For each word, we generate Q, K and V from its embedding (or the output of the previous encoder layer) by multiplying it with the trained Wq, Wk and Wv metrics.
Then we calculate the attention for each word using the algorithm described below.

Questions: What does Query, Keys and Values represent?
Query:
Multiheads attention
Residual connection
https://stats.stackexchange.com/questions/321054/what-are-residual-connections-in-rnns
My takes aways of the Transformer
Benefits
- Parallelism across sentences. The only sequential part is the decoder within each sentence.
Limitations
- The Transformer only considers context within a sentence, no cross sentence context is considered.