BERT与语义理解发展史
最初,有了word embedding思想。它是想把词映射到onehot vector,再把onehot vector映射到一个向量空间。类似于feature提取。
如何训练Word embedding
起初,人们用语言模型来训练word embedding。语言模型,说白了,就是给出上文,让你预测当前的词是什么。
最简单的训练方法,就是把word映射到onehot vector,再把onehot vector映射到向量空间,再加一些neural networks,最后softmax输出一个onehot vector,作为当前值的预测。
后来有了word2vector,它用当前词的上下文,来预测当前词,也即CBOW(continuous Bag-of-words model)。
但是word2vector无法解决多义词的问题,它没有语境信息。
ELMO
ELMO给出了语境问题的解决方案。它用了两层双向向的LSTM。不仅能输出一个单词embedding,还能输出单词在句子中的句法特征,和语义特征。
ELMO的缺点,LSTM抽取信息能力弱于Transformer
GPT
用Transformer做单向信息抽取。
GPT的缺点:没有用双向(正向、反向)抽取
BERT
双向,transformer抽取语义。
Transformer很可能在未来取代RNN与CNN成为信息抽取的利器。
zhuanlan.zhihu.com/p/49271699
Attention注意力模型的强大应用
起初,我们用encoder,decoder来encode语句到语义上, 在decode语义到下游任务中。
比如:输入是中文,输出是英文,这就是翻译系统。
输入是文章,输出时摘要,这就是摘要系统。
输入是问题,输出是答案,这就是QA问答系统,对话机器人。
输入是图片,输出是文字,这就是图片自动描述系统。
输入是语音,输出是文字,这就是ASR系统。
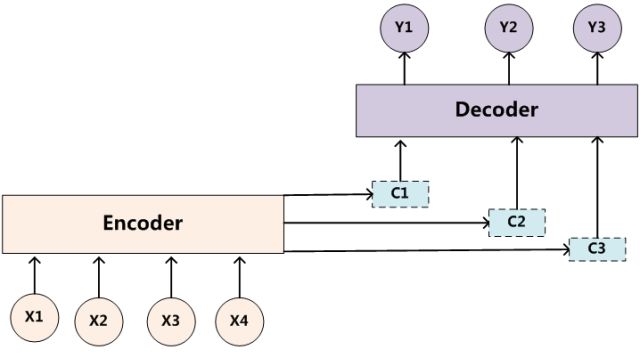
Encoder-decoder的缺陷:所有的输入词的权重都是一样的,没有区别。
Attention模型
Soft Attention
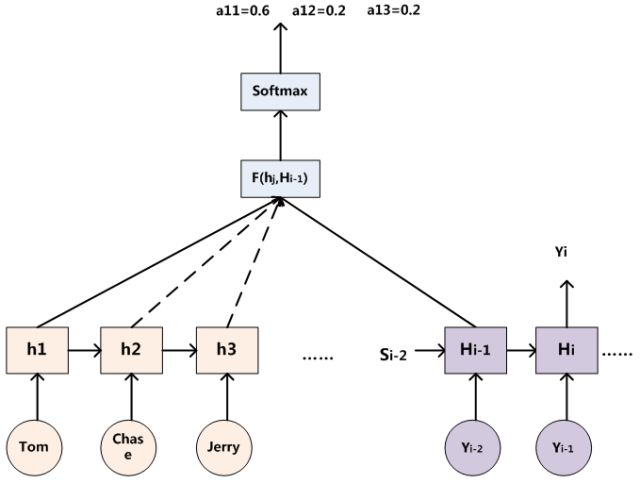
以自动翻译为例,在翻译到目标文本的每个词时,encoder出来的语义Ci都会跟着变化,因为source里的每个单词对当前要翻译的词的贡献度不同
先举个例子说明什么是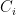

在翻译“chase”时,chase所占的注意力(0.6)自然比其他的单词”tom – 0.2″”jerry – 0.2″所占的注意力要高。
f2表示encoder对于输入单词的变换函数,如果encoder是RNN的话,他就代表着某个时刻输入
g一般是个加权求和公式

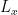
我们以RNN作为encoder和decoder为例
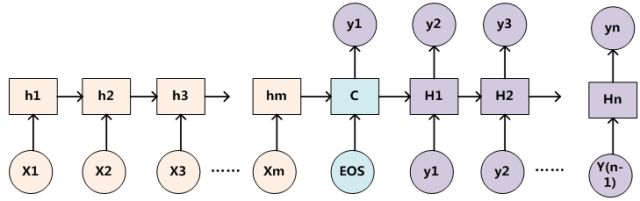
那么如何找到输出target单词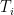
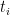
让我们把时间退回到t-1,此时在生成
zhuanlan.zhihu.com/p/37601161